When it comes to social media for business, there is one question on everyone’s mind: Who are the influential people in my area? Unfortunately answering this is easier said than done. Take Twitter for example. You could look at a user’s total followers or the number of lists they are on, but those are blunt instruments at best. When you’re focused on a specific topic, those numbers can be downright misleading.
After mulling this over, I figured a good measure of potential influence would be how well networked a person is in a particular topical environment. To test this hypothesis I decided to look at an area I know pretty well: the Washington DC tech scene. Since I already have a good sense of this community, I could verify the analytical results from my own knowledge.
The Results
After doing my analysis, here is my ranking of the top ten most networked individuals:
| Rank | Handle | Name | Relationships | Followers |
| 1 | corbett3000 | Peter Corbett | 671 | 7,980 |
| 2 | dcconcierge | Shana Glickfield | 644 | 5,979 |
| 3 | FrankGruber | Frank Gruber | 571 | 27,172 |
| 4 | cheeky_geeky | Mark Drapeau | 539 | 19,652 |
| 5 | DCeventjunkie | Lisa Byrne | 492 | 5,755 |
| 6 | shashib | Shashi Bellamkonda | 482 | 14,287 |
| 7 | digiphile | Alex Howard | 462 | 78,433 |
| 8 | alexpriest | Alex Priest | 427 | 4,940 |
| 9 | SteveCase | Steve Case | 414 | 416,114 |
| 10 | digitalsista | Shireen Mitchell | 408 | 7,562 |
Overall, this squares pretty well with my knowledge of this community. Number one, @corbett3000, belongs to none other than Peter Corbett, the CEO of iStrategyLabs, a leading DC technology firm and organizer of many DC tech conferences (including the upcoming 10-day DC tech festival). Coming in second is Shana Glickfield, who goes by @dcconcierge, and is DC’s consummate networker and FOMO sufferer. Rounding out the top three is Frank Gruber, @frankgruber, CEO of TechCocktail.com. Number four is every one’s favorite Microsoft staffer, Mark Drapeau who tweets at @cheeky_geeky.
It is particularly interesting to see how a large Twitter following does not necessary translate into a significant number of relationships within this particular network.
For kicks, I threw the top forty accounts into NodeXL to see what the network looks like:
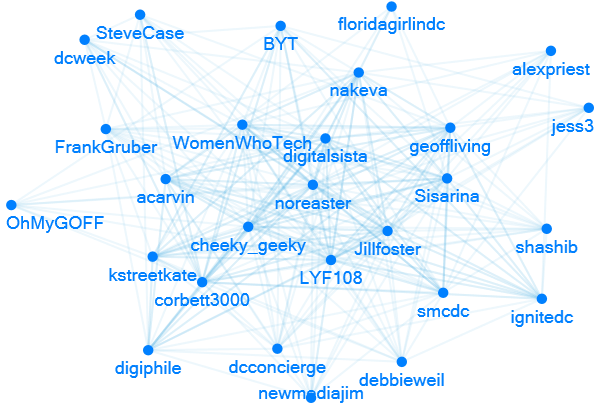
Methodology
And the big question: how did I arrive at these results? Here is the process I used:
- My starting point was trying to figure out how to measure the number of connections within a particular geographic region and subject area. For this, I needed a good index of who was active in the DC tech sphere on Twitter. Fortunately, this part of the job has been done by the community in the form of Twitter lists. I trolled through a large selection of Twitter lists looking for ones that had “DC” and either “social media” or “technology” and entered those info my database.
- I then went through each list and saved all the individual accounts on that list.
- From the users on these lists, I ended up with a database of about 2700 Twitter accounts that, through the Twitter lists, were related to the DC tech scene.
- In the most time-consuming part of the analysis, I set-up a system to download all the people these Twitter accounts followed. Since a follow is an expression of interest in the followed account, I counted that as a “vote”. This is much the same way Google considers a link a vote of confidence in the linked page.
- After a few days of downloading data from Twitter, I had a database of nearly 2 million follower-to-followed relationships. Using this index, I checked which accounts were most frequently followed and ranked them according.
- I was able to automate nearly every set after selecting the Twitter lists, but the final step requires a good deal of “eyes on screen”. The final list included a number of very widely followed accounts, but not ones I was interested in. Since I was only focusing on individuals in DC, I removed a lot of institutions and people outside of the city. For example, the top three @mashable, @barackobama, and @techcrunch are all widely followed, but not members of the DC tech scene. As such, I excluded these from the final results. (It is interesting that Mashable has a much wider following in DC than Techcrunch. I imagine if I was looking at Silicon Valley the ranking would be inverted.)
I was able to automate most of the above steps using a small app I coded, so much of the data collection took place while I was fast asleep in bed. Due to Twitter API data call limits, most of this was done using automated CRON jobs. Steps 1 and 6 though were not automated and required diligently going through the data.
Final Thoughts
So that’s it? Certainly not, this only measures who is widely followed within this topical subset, not who is actually influential. You’d need to combine this with other measures (frequency of retweets, ability to drive conversations, and so on) to get real sense of influence.
Fortunately the results do square pretty well with my understanding of the DC tech scene, which helps validate the approach. Most likely I’ll do some more playing around with this technique, so stay tuned.
It’s so interesting to see my community connected like that. Thanks.
Fascinating and a lot of work – kudos!!
Thanks! I’m still playing around with the methodology and exploring ways to include other metrics, so hopefully there will be updates. I do wonder how this ranking matches up with other analysis (particularly Klout and Backtype).
Thanks for all your hard work on this… love seeing how connected everyone is to each other in this community.
This is rad. Really interesting post Darren!
Good to see you parse out networking vs influence, as otherwise, I’d wonder how @acarvin was left off of your top 10. Interesting to see the absence of political or congressional accounts; this really is about DC tech.
One note regarding networking: who you follow may not always square with the people some one might be connected to via Twitter, because of lists.
With respect to large followings, as with Case, this analysis looks like it focused upon how many DC tech accounts a given individual followed; as a result, follower numbers are substantially less relevant.
In general, given that I’m still a relative newcomer on the scene, I’m glad to see I’m in the mix. Thank you for sharing your results.
Can you share the full dataset? Would love to see it.
Interesting study. Thanks for including me on it. I would be interested to see the study applied nationally to see where the DC Technorati fall. I am sure Steve Case would be a lot higher on the list. :)
@Alex Yes, this was pretty focused on the DC technology community. Andy comes in at #13. Certainly this is only one perspective, which is why I was careful to say these are the best “networked” rather than the most “influential”. Check out the longer and more complete list to see where others stand. There are journalists and political groups on the list, but I filtered those out.
@Rebecca Sure, how would you like it? I can give you the full SQL data. I could also produce a longer list like the one I mention above.
@Frank I’ll see what I can do!
This report obviously didn’t take into account how much more I like Shana than Peter :-P
Darren – Thanks for investing the thoughtfulness and time; really interesting.
Dang I guess I have to step my game up
Steve Case should be pleased to bein such great company! :)
Finally recognized in the category which I thrive — NETWORKING!! ;-)
It’s interesting because I see the DC Tech scene thriving in so many subcategories — Nonprofit tech, Startup tech, Gov 2.0, real time journalism, Crisis communications, etc. It’s fascinating (and exhausting) to keep up with it all! You wouldn’t see those sub categories nearly as prevalently in other cities which is why DC is so awesome.
Darren – Thanks for insane amounts of number crunching it took to look at networks instead of “influence”!
Joe – Thanks for liking me more than your brother Peter. ;-)
Hi Darren,
Thanks for the ha\rd work on this..I think your model can probably be used to to identify individuals in Nonprofit tech, Startup tech, Gov 2.0, real time journalism, Crisis communications as Shana says DC is thriving.
In the entire list it was interesting to see Mashable has mpre relationships than @barackobama ;) You have proved your brilliance in starting an a analysis based in data and relationships. Hope there is more to come.
Thanks,
Shashi
Thanks so much for this, Darren! Really cool analysis, I’m thrilled to be in such awesome company. God knows I never thought I’d show up on a list like this.
I just work here. Thanks!
Measuring influence is a cool problem. If you have good knowledge of the network, one important parameter is the topology of the graph: not only who is linked to whom, but who is linked to THEM, and so on (PageRank, essentially). However your sorta stripped-down PR may be good enough (and much more feasible, practically, for big data). On top of that, some combination of retweets, lists, replies, rollower/following ratio, general tweet activity etc. should be taken into account.
Measuring “influence” is very hard, mainly because no one can agree on what it is. For example, what Alex Howard said above is kind of true, Andy Carvin is indeed seen as very influential by some people. However, lately he has become less influential to me even though we know each other fairly well and are connected to each other online, I don’t particularly care about the minute to minute news out of the Middle East.
What I think can be measured and is meaningful that goes beyond this is word of mouth, literally, how does information flow through the graph? Lately, for example, Andy Carvin’s information is not flowing through me to other people. If he started telling jokes about people he works with at NPR, or doing local restaurant reviews once in a while, maybe it would again. So it’s temporal.
On the other hand, I share lots of information from Alex and Peter Corbett (as well as others on this list) all the time because they’re closer to my interests. However, that’s temporal too – I’m less interested in, say, Open Government than I was two years ago, and more interested in politics and non-profits.
It’s also hard to deal with people you want to leave out of the graph. As a scientist, you’d deal with “outliers” by including them and not including them and showing both, generally… There are other statistical ways to deal with such things. I think it makes sense to leave out, say, Mashable, since it’s not a person. But one dimension that seems to have been left out is the notion that information could flow between two “DC” people via an intermediary outside DC that wasn’t picked up in the initial screen. In other words, a scenario where (say) Peter Corbett tweets lots of stuff I like, but at 3pm when I’m not reading; someone else from California RT’s it around 6pm when I am reading, then I RT that. So Peter and I are connected but the information flows indirectly, therefore making that CA person effectively part of the DC Tech social graph.
Anyway, I’m just writing this because I think this stuff is cool and it’s something I’ve given some thought to.
Thanks hugely for all your work on this. Thrilled – and also fascinated – to be included.
Very cool. Wasn’t aware of NodeXL – wonder what type of data I could get back if I threw the GovTwit dataset at it….
Thanks everyone for the great comments. I wasn’t quite expecting this level of response!
@Shana It certainly is interesting to see the diversity of subject areas that were included in the top accounts. I think I’ll try running this on a couple of other cities to see if I get a similar result. I’ve run this on a few countries and it’s been fascinating to see the unique ways communities use Twitter in different environments.
@John Definitely agree, this experiment is only a small slice of the myriad of the indices you’d need to measure true “influence”. The challenge of “big data” is a real one though. This project resulted in about two million database entries, making the crunch rather complex and time-consuming. I actually talked to a few local consultancies when doing this and when they tried to crunch the data it crashed a couple of their computers.
@Mark I think the biggest challenge is knowing what sort of “influence” you’re looking for and what to measure. There are a great many types of influence, and depending on your program objectives, the ways to measure can be quite different. For example, you may want people to take a specific action (say, voting a particular way) or you may merely want them to be better informed on a topic. For the former, compelling writing or a strong call to action would be more influential. On the latter, a large network with the right mix of people would be better.
With regards to Andy, I like your point about the temporal nature of influence. When I was doing reporting on the events during the Arab Spring, Andy was one of the most important sources I relied upon (along with Al Jazeera). Now that my work has moved on, there are others in my network who are much more “influential”. This is part of the reason I’m so wary of Klout and the like. It doesn’t take into account how influential someone is on a particular topic or within a specific community. Someone may be very influential in knitting circles, but that isn’t going to have much impact on me. (I will say that Klout’s new “topics” feature is compelling and potentially more useful than their single numerical score.)
The geographic division is definitely somewhat arbitrary considering the somewhat borderless nature of the web. When researching Egypt and Tunisia, I saw a lot of connections between notable activists in both places and I’m sure there was much knowledge sharing between the groups. That said, the biggest jumps in Twitter followers I’ve gotten were after speaking at conferences, mostly here in DC and from DC-based people. So there is some legitimacy for making a geographic division.
@Steve It’d be great to see what you can get out of your GovTwit dataset. The one caution is NodeXL only handles about 8000-10000 rows of data (at least on my marginal hardware), so it is tough to display a lot of data. There are more robust tools out there which I need to explore.
Great work Darren. I love this stuff.